Anthropic bets on workflow, not weight, with Claude Science workbench
Anthropic's new Claude Science product is less a model release than a packaging play — a single workbench that hooks the lab's language models into the databases, code runners, and file systems where modern research actually happens.
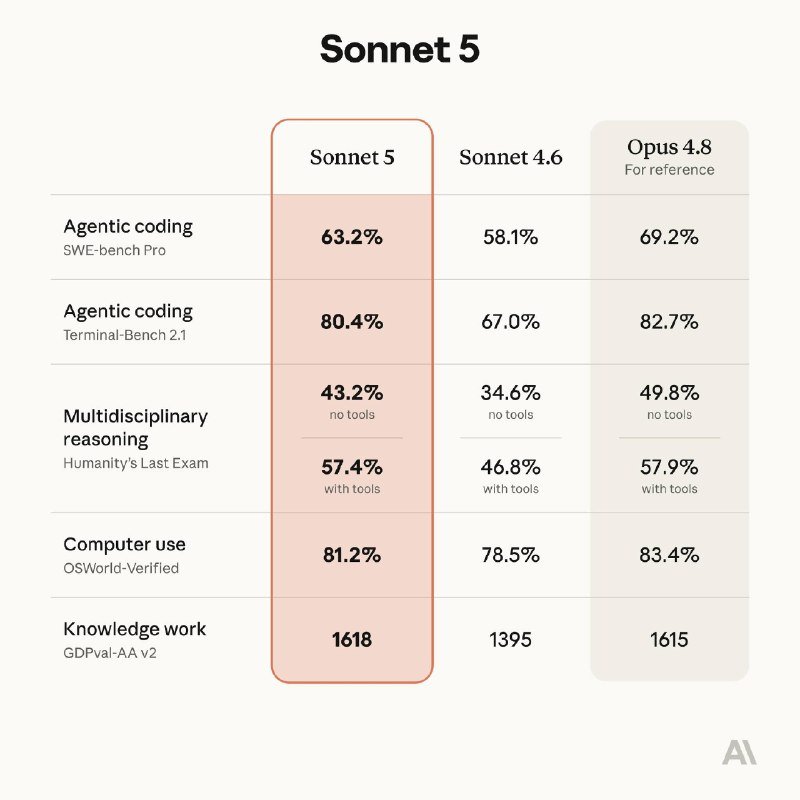
Anthropic pushed two products into the open in the space of four hours on 30 June 2026. The first, Claude Sonnet 5, is the kind of release the lab's rivals now treat as a punctuation mark — a generational bump framed, in Anthropic's own marketing, around stronger agentic and coding capabilities. The second, Claude Science, is the more interesting move. It is not a new model at all. It is a workbench.
The distinction matters. The dominant story in frontier AI for the past two years has been the model arms race — parameter counts, context windows, benchmark scores, and the trillion-dollar infrastructure build-out required to keep the curve bending. Anthropic's pitch with Claude Science is that the bottleneck is shifting. The models are competent. What researchers actually lack is a coherent environment to use them in. The lab is betting that the next layer of value will be captured at the workflow seam, not at the weight layer.
What was actually launched
At 20:32 UTC on 30 June 2026, CryptoBriefing's news wire carried Anthropic's announcement of Claude Sonnet 5, billed as having stronger agentic and coding skills than its predecessor. Four minutes later, the same wire carried a separate release for Claude Science, an AI workbench built for researchers. By 04:45 UTC on 1 July 2026, industry chatter on X (via Roundtable Space) had compressed the framing into a single slogan: Claude Science "doesn't talk to you about science, it does it with you."
The substance, as described by TechCrunch in its own coverage, is a workbench that gives scientists "one environment to do computational research, saving them from the need to bounce between databases, pipelines, and tools." In practice that means the product connects to over 60 scientific databases, runs analyses inside the same interface, and — critically, for reproducibility — saves the exact code behind every figure the model produces.
The reproducibility point is not throwaway. The replication crisis in academic science has been a documented concern for the better part of a decade, with whole subfields from psychology to cancer biology admitting that a non-trivial share of published findings cannot be reproduced from the methods sections alone. A workbench that captures the executable provenance of every chart a researcher generates — not the prose description of it — addresses that complaint directly. It also locks in a different kind of moat: not the model, but the institutional habit.
Why the workbench framing is the real story
Sonnet 5 is the headline because frontier model releases are how AI labs compete for talent, capital, and column inches. The workbench is the strategic move, because frontier model margins are about to compress.
Three converging pressures make the case. First, the cost of training state-of-the-art models is now measured in single-digit billions of dollars per generation, and the marginal return on each additional training run is flattening — the same observation that drove the so-called "scaling plateau" debate through 2024 and 2025. Second, open-weights competitors from Meta's Llama line, Mistral, DeepSeek and a thickening long tail of Chinese and Middle Eastern labs are compressing the price floor for capable models. Third, the enterprise procurement market — which is where AI labs actually make money — does not buy raw intelligence. It buys software that slots into existing workflows, with audit trails, permissions, and integration points.
A workbench built around scientific databases, code execution, and figure-level reproducibility is precisely the kind of product that procurement officers can defend. It looks like an instrument, not an experiment. That is the sales motion Anthropic is choosing to optimise for.
There is a counter-reading worth airing. Some of the most capable AI research tools of the last two years — the NotebookLM product at Google, the Elicit platform, the Allen Institute's own science-tuned releases — have struggled to convert researchers into paying users at scale. The audience is small, the procurement cycles at universities are glacial, and the buying decision is often made by a principal investigator with a credit card rather than a CIO with a contract. Anthropic's bet that scientific workflows are the wedge into broader enterprise penetration could miss as easily as it could land. TechCrunch's framing — "bets on workflow, not a new model, to win over scientists" — captures that open question rather than answering it.
The geopolitics underneath the interface
The workbench framing also reads differently depending on where you sit. From San Francisco, it looks like Anthropic continuing the playbook that has made the lab the highest-valued private company in AI: ship a capable model, wrap it in a developer experience that is materially better than the competition's, and price for trust. From Beijing, the same release lands inside a different conversation. Chinese AI labs have spent the last eighteen months emphasising domestic capability — DeepSeek's open-weights models and Alibaba's Qwen series have been the visible flagships — and a Western lab shipping an integrated "AI scientist" workbench is the kind of product category that Chinese policymakers would prefer to see matched by a domestic champion rather than imported.
That structural friction is worth naming, because it shapes the export-control and standards-setting battles that will define the next phase of AI competition. The harder a frontier-lab product becomes to substitute with an open-weights alternative — and a workbench, with its accumulated integrations and audit logs, is structurally harder to substitute than a raw model — the more leverage the lab holds in conversations about compute access, API restrictions, and cross-border data flows.
What remains uncertain
The press materials and the wire coverage describe what Claude Science is. They do not, at this point, settle three questions that will determine whether the product matters.
First, pricing and access tier. Anthropic has not, in the materials cited here, specified whether Claude Science will be available through a researcher's existing Claude subscription, an enterprise seat, or a separate academic pricing programme. That matters because the historical pattern in scientific software — Matlab, Stata, even Python distribution before Anaconda — is that the pricing model determines the user base.
Second, the database list. "Over 60 scientific databases" is the figure in the announcement. The composition of those sixty — public versus commercial, US versus international, curated versus raw — will determine how useful the product is in fields from genomics to materials science where the relevant corpora live behind paywalls or institutional agreements.
Third, the durability of the "agentic" framing for Sonnet 5. The phrase is doing heavy lifting across the lab's own marketing and the wire coverage. Whether the new model actually delivers on agentic task completion at production-grade reliability — or whether the capability remains, as it has for most 2025-vintage models, impressive in demos and brittle in deployment — is a question no press release can settle. The published benchmarks, when they arrive, will be one input. The slow accumulation of independent third-party evaluations will be the other.
Stakes
If the workbench play works, Anthropic captures a layer of the AI stack that competitors will find difficult to dislodge — the same way that Salesforce captured the CRM workflow layer in the previous decade despite never winning the database war. If it does not, the lab will have spent meaningful capital on a product category where the addressable market is narrower than the marketing suggests, while competitors in China and the open-weights ecosystem continue to close the raw-capability gap.
For researchers, the immediate question is more practical: is the workbench a place to do real work, or another demo-grade interface that fades once the novelty wears off. The reproducibility tooling — code attached to every figure — is the part most likely to outlast the launch cycle.
Desk note: this article was framed around the workflow-versus-model distinction because that is the analytically durable read of the day's announcements. The model release is the headline the wires chased; the workbench is the move that will determine whether Anthropic's enterprise moat thickens or thins over the next four quarters.
Wire provenance
This editorial synthesis draws on the following public wire/social posts:
- https://t.me/CryptoBriefing
- https://t.me/CryptoBriefing