Anthropic's Claude Sonnet 5 lands as the agentic race enters a pricing war
Anthropic released Claude Sonnet 5 on 30 June 2026, leaning hard into agentic workflows and undercutting premium tiers. The launch says less about raw intelligence than about who can keep the lights on while models start doing the work.
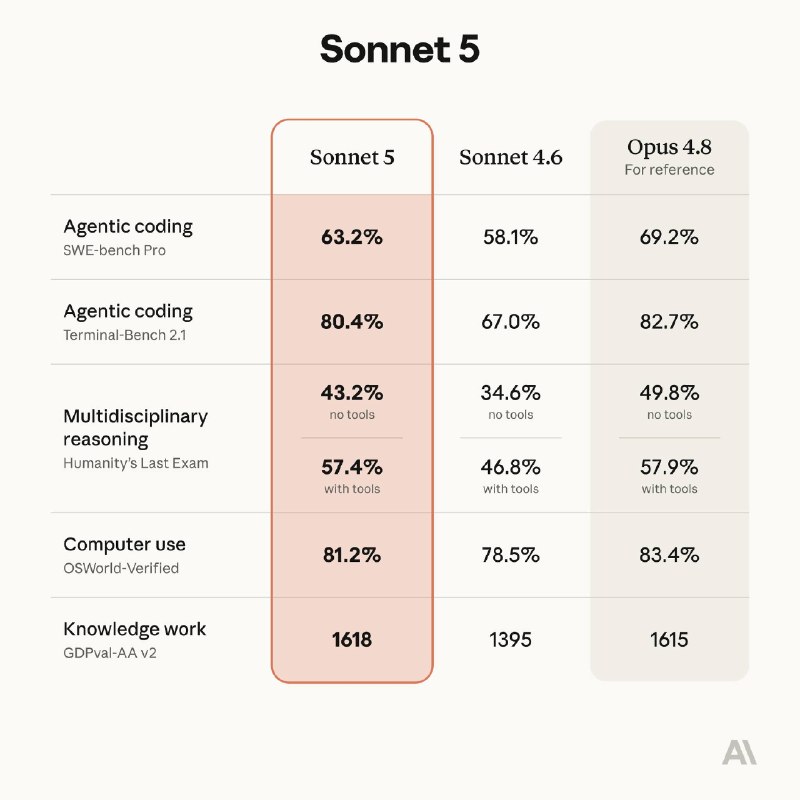
Anthropic unveiled Claude Sonnet 5 on 30 June 2026 at roughly 18:00 UTC, a mid-cycle upgrade built not to dazzle on benchmarks but to do work autonomously. Within hours the company's messaging had crystallised: the new model can plan multi-step tasks, browse the web, call tools, use terminals, and run agentic loops without constant human supervision. The launch lands in a frontier-model market that has spent the last six months fighting on three axes at once — capability, safety, and price — and Anthropic has chosen to contest the third most aggressively.
The bet is straightforward. Frontier labs spent 2024 and 2025 racing to demonstrate ever-larger reasoning scores; by mid-2026 the bottleneck has moved. Customers do not need a model that writes prettier essays. They need one that can be handed a Salesforce account, a Postgres database, and a vague objective, and that will return hours later with the work done. Sonnet 5 is Anthropic's clearest statement yet that the next unit of competition is the agent.
What Sonnet 5 actually is
According to the launch coverage on TechCrunch, Anthropic is positioning Sonnet 5 as a cheaper alternative to its own flagship Opus tier, to OpenAI's GPT-5.5, and to Google's Gemini Pro. The model carries stronger agentic capabilities, lower per-token pricing, and improved safety guardrails, in that order of emphasis. Anthropic's framing, echoed by the AI Post channel on Telegram, treats Sonnet 5 as the "smartest and most agentic Sonnet yet" — a deliberate double claim that the model is both more capable than its predecessor and more useful in the kinds of autonomous workflows enterprise customers are now asking for.
The shift in emphasis matters. A year ago, Anthropic's product narrative centred on safety and constitutional training. The Claude 3.5 generation softened that into a generalist pitch. Sonnet 5 is the first release where "agentic" — meaning capable of planning and executing multi-step tasks with minimal supervision — has moved to the headline. Capability still matters, but as a means to the end of autonomy.
The pricing tell
The most consequential number in the launch is not a benchmark. It is the per-token cost. Anthropic's mid-tier model undercutting its own premium tier is a familiar pattern in cloud software — AWS does it quarterly with Graviton chips, Google does it with TPUs — but in frontier language models it is a relatively recent move and a strategically loaded one.
Two readings are plausible. The first is that Anthropic has hit an efficiency wall in training and is now competing on inference economics the way hyperscalers do. The second is that the company has concluded the enterprise market will not pay a premium multiple for marginal intelligence gains once a model is "good enough" to drive a workflow end-to-end. Both can be true at once. The TechCrunch coverage notes that the pricing posture is itself part of the pitch — Sonnet 5 is meant to be deployed at scale inside organisations that previously treated frontier models as a research line item rather than a production one.
The counter-narrative: agents are not yet a product
The agentic framing is not uncontested. Inside the developer community the consensus on 30 June 2026, judging by the AI Post round-up, is that "agentic" still means "the model will confidently do the wrong thing for longer." Multi-step autonomy multiplies the surface area for hallucination, and each tool call adds a place where the loop can drift. Anthropic's own safety claims for Sonnet 5 are explicitly framed around reducing that drift, but no frontier lab has published convincing evidence that agentic reliability is solved.
There is also a structural counter-narrative that the launch coverage does not foreground. The bigger labs — OpenAI, Google, Anthropic — have an incentive to define the frontier as "agents," because that is the workload most likely to lock customers into a single provider's tool ecosystem. An agent that browses the web, calls APIs, and writes code is not really using a model; it is using a platform. Whoever owns the agent owns the workflow. Pricing wars at the model layer are partly a way to win a platform war at the integration layer.
Stakes
If Sonnet 5 holds up under enterprise load, the immediate losers are the boutique labs selling thin wrappers around existing APIs and the consultancies that have been charging six figures to glue OpenAI calls into corporate workflows. The medium-term losers, if agentic reliability keeps improving, are the BPO and RPA vendors whose value proposition was that human-in-the-loop automation was the only kind that worked.
The bigger structural question is whether agentic deployment accelerates or slows the consolidation of the model market. On the reading that agentic workloads favour incumbents with deep platform stacks — Anthropic, OpenAI, Google — the launch tightens an oligopoly. On the reading that open-weights competitors (Mistral, the Chinese labs, Meta's Llama line) can match Sonnet 5 on capability at half the price within two quarters, the launch accelerates commoditisation. The sources do not resolve this. They simply mark the moment at which the question became unavoidable.
What the 30 June launch does settle is the framing for the next twelve months. The frontier-model race is no longer a benchmark race. It is an agent race, and the companies that survive it will be the ones that can price autonomy at a level enterprises will actually pay for.
Desk note: the wire coverage of Sonnet 5 reads like a capability story; this publication reads it as a pricing story dressed in capability language.
Wire provenance
This editorial synthesis draws on the following public wire/social posts:
- https://t.me/aipost
- https://x.com/roundtablespace/status/HMFJYt8XEAAYMDz